OpenPIM API
Introduction
What is an API
An API (Application Programming Interface) provides a set of methods (requests) for interacting with specific software. This interface enables programs to interact with your software, perform operations such as search, save, delete, etc., through specific methods provided by your API.
Using an API, you can perform various operations related to managing product information. It allows you to retrieve information about products, add new products, manage categories and attributes, and so on.
What is GraphQL
GraphQL is a query language for APIs that allows you to request only the data you need. The principle of GraphQL is based on the flexibility and efficiency of data transfer between the client and the server.
The GraphQL schema that OpenPIM supports can be found here.
Advantages of GraphQL include:
Query Flexibility: Unlike traditional REST APIs, where each endpoint has a fixed structure and returns predefined data, in GraphQL, the client can request only the data it needs. This helps to avoid "over-fetching" and "under-fetching" issues.
Uniform Interface: In GraphQL, all requests look the same regardless of what they request. Queries are structured as a tree, where the client specifies only the fields and connections it's interested in. This makes the API more understandable and convenient to work with.
Data Relationships: GraphQL allows you to describe complex data relationships and perform deep queries to fetch data from multiple connected objects in a single request. This simplifies working with data that has a complex structure or relationships.
Developer Tools: There are many tools available for working with GraphQL, including tools for developing client applications, query debugging tools, documentation generators, and more. This makes the process of developing and debugging APIs more efficient.
Query Examples
Type Query
In GraphQL, there are two types of queries: data retrieval and data modification.
The query type name is a keyword that specifies the type of query. In this case, it is Query, indicating that these operations are intended for reading data. Below is an example.
type Query {
search(requests: [SearchRequest]!): SearchResponses!
getSearchByIdentifier(identifier: String!): SavedSearch
getSearches(onlyMy: Boolean!): [SavedSearch]!
getColumns(onlyMy: Boolean!): [SavedColumns]!
getColumnsByIdentifier(identifier: String!): SavedColumns
}
2
3
4
5
6
7
Each query type contains a set of fields that the client can request. Fields define what data can be obtained in response to a query. In this case, the fields include:
- search - Search for requests with returning responses.
- getSearchByIdentifier - Retrieve a saved search by its identifier.
- getSearches - Retrieve a list of saved searches.
- getColumns - Retrieve a list of saved columns.
- getColumnsByIdentifier - Retrieve saved columns by their identifier.
Some fields may take arguments that are used to customize the query. For example, getSearchByIdentifier takes an argument identifier, which specifies the identifier of the saved search to retrieve.
Return Types: Each field has a specific data type that it returns. For example, getSearches returns an array of objects of type SavedSearch.
Exclamation Mark (!): In GraphQL, the exclamation mark denotes the mandatory nature of a field or data type. For example, [SavedSearch]! means that the returned list of saved searches cannot be empty.
To retrieve data about any product, you need to compose a Query request. An example of such a request is provided below:
query { search(
requests: [
{
entity: ITEM,
offset: 0,
limit: 10,
where: {typeIdentifier: "item",values: {size: {OP_gt: "118"}}},
order:[["id", "asc"]]
}
]
){
responses {
... on ItemsSearchResponse {
count
rows {
identifier
name
values
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
In this query, it represents an array of objects, each of which contains specific parameters for performing a search request. In this case, the array contains one element:

entity - defines the type of entity for which the search will be performed. In this case, the value ITEM is specified, which likely indicates a search for items (products) in the system.
offset - determines the offset (index) from which the selection of search results begins. In this case, the value 0 is specified, indicating that the selection starts from the beginning.
limit - specifies the number of results to be returned in response to the query. In this case, the value 10 is specified, meaning that no more than 10 results are returned.
where - defines the conditions for filtering search results. In this case, a condition is specified based on the type (typeIdentifier) and the size value of the item. This field allows for searching items based on any attribute specified in the system, whether it's name, identifier, or the value of one or several attributes.
- typeIdentifier: Defines the type of identifier used for filtering. In this case, the value "item" is specified.
- values: Contains the values for filtering. In this case, the size value is specified, which is compared using the OP_gt (greater than) operator with the value "118".
See more details in the Query Language section.
order - determines the order in which the results should be sorted. In this case, it is specified that the results should be sorted in ascending order (asc) based on the identifier (id) of the item.
Field responses in this query defines the expected structure of data that will be returned in response to the query execution. Here, the ... on operator is used, which allows specifying the expected response type. In this case, an object of type ItemsSearchResponse is expected. Let's take a closer look at each field in the responses object:

count - This field contains the number of items that match the executed search query. For example, if the query was for searching products, this field will contain the count of found products.
rows - This field contains an array of objects, each representing a found item. Each object contains the following fields:
identifier: The identifier of the item. It can be a unique identifier or some other identifier that uniquely identifies the item.
name: The name of the item. This field contains the name or title of the item, which can be used for display purposes.
values: The values of the item. This field contains additional values or characteristics of the item. For example, it could be a set of attributes or properties of the item, such as price, size, color, etc.
Each field in the rows object represents information about one found item.
As a result of this query, the program will output information about the product to the console, where the "size" attribute has a value greater than 118.
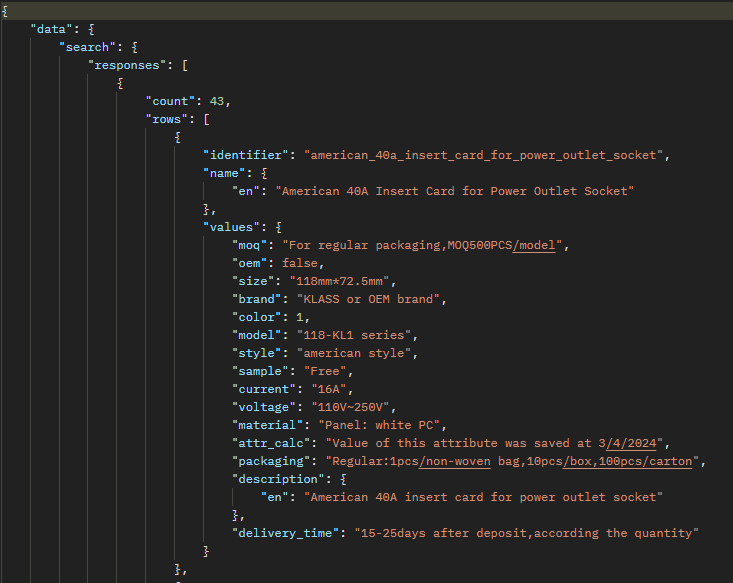
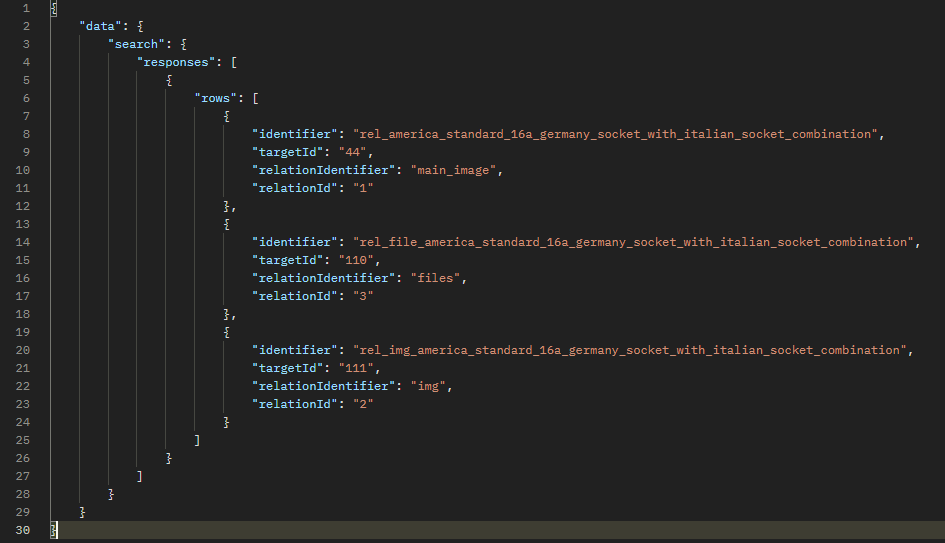
There is also the possibility to request relationships associated with products. In the example below, a request is made to retrieve relationships for a specific product. For this purpose, the entity type ITEM_RELATION is used.
In the where field, the value of the product identifier whose relationships need to be displayed is specified.
query {
search(
requests: [
{
entity: ITEM_RELATION,
offset: 0,
limit: 10,
where: {itemIdentifier: "america_standard_16a_germany_socket_with_italian_socket_combination"}
}
]
){
responses {
... on SearchItemRelationResponse {
rows {
identifier
targetId
relationIdentifier
relationId
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
The expected result of this query includes:
- identifier: The identifier of the relationship between the items.
- targetId: The identifier of the target item of the relationship
- relationIdentifier: The identifier of the relationship.
- relationId: The identifier of the related item.
The response will be a list of existing relationships.
Import request
Let's consider an example of a data modification request. The key term here will be mutation. In this example, we're looking at changing the value of the "color" attribute for items where the "color" value is equal to 4.
First, let's apply a search query similar to the example described above.
query { search(
requests: [
{
entity: ITEM,
offset: 0,
limit: 1000,
where: {values: {color: 4}},
order: []
}]
) {
responses {
... on ItemsSearchResponse {
count
rows {
identifier
name
values
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
As a response, we received an array of items with a "color" value equal to 4. Changes to the values will occur for those items whose identifiers will be substituted in the following request.
Next, let's compose a request using mutation.
mutation{ import(
config:{
mode: UPDATE_ONLY
errors: PROCESS_WARN
},
items:[
{
identifier: "<The identifier of the item being updated.>",
values: {color: 1}
}
]
) {
items {
result
id
errors { code message }
warnings { code message }
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import - The name of the mutation. In this case, it's the name of the operation.
config - An object containing settings for data import.
mode - The mode of data import. In this case, it's the update mode (UPDATE_ONLY), which means that only existing data will be updated, and new data will not be added. Some alternative modes include:
- CREATE_ONLY - Create only new items. If an item already exists, an error occurs.
- CREATE_UPDATE - Create new items and update existing ones. If an item exists, it will be updated; otherwise, a new one will be created.
- DELETE_ONLY - Delete items. This mode is used for data deletion.
- APPEND - Append data to existing items, if applicable.
errors - Error handling. Here it is specified that in case of errors, the processing should continue (PROCESS_WARN).
items - an array of items to be imported.
identifier - the identifier of the item. The identifiers obtained from the search for items matching the specified condition will be used to make changes. This is necessary to iterate through all the values obtained from the search query.
values - an object containing the values to be updated for the item.
color - the color value. In this case, the value is set to 1.
Thus, after executing the described queries, the values of the "color" attribute will be changed in the system. Where previously the value was "4", it will now be set to "1".
Postman examples
This is a popular tool for developing and testing APIs. It provides a convenient interface for creating, sending, and debugging HTTP requests, as well as for automating API testing.
Below is a Postman collection containing some types of requests described above. Postman examples
Node JS examples
The attached archive contains an example of a Node.js request created. For detailed information, please refer to the README.txt file included in the archive.
The provided code makes a request for mutation of all elements where the value of the "size" attribute equals "118". Thus, when a product meeting the conditions is found, the "-" value in the "voltage" attribute of the element will be changed to "~".
The server.js file contains functions related to communication with the server and user authentication for the GraphQL server.
The main.js file demonstrates the use of functions exported from server.js to perform specific tasks:
- User authentication
- Item search
- Item update
This code illustrates a typical scenario where a user logs into the system, searches for specific items, and updates their data using the GraphQL server.
Python examples
The archive contains an example of a Python request. For detailed information, please refer to the README.txt file included in the archive.
In these examples, elements are searched based on the "color" attribute, and the value of this attribute is changed when a certain condition is met.
The search.py file contains functions for searching elements on the GraphQL server. It includes the following main components:
- Search query
- Sending the request
- Handling the response
The mutation.py file contains functions for performing mutations on the GraphQL server. It includes the following main components:
- Mutation formation
- Sending the request
- Handling the response
Both files provide convenient interfaces for performing searches and mutations on the GraphQL server, facilitating interaction with data on the server and updating them through the API.