Import
Loading objects into the system
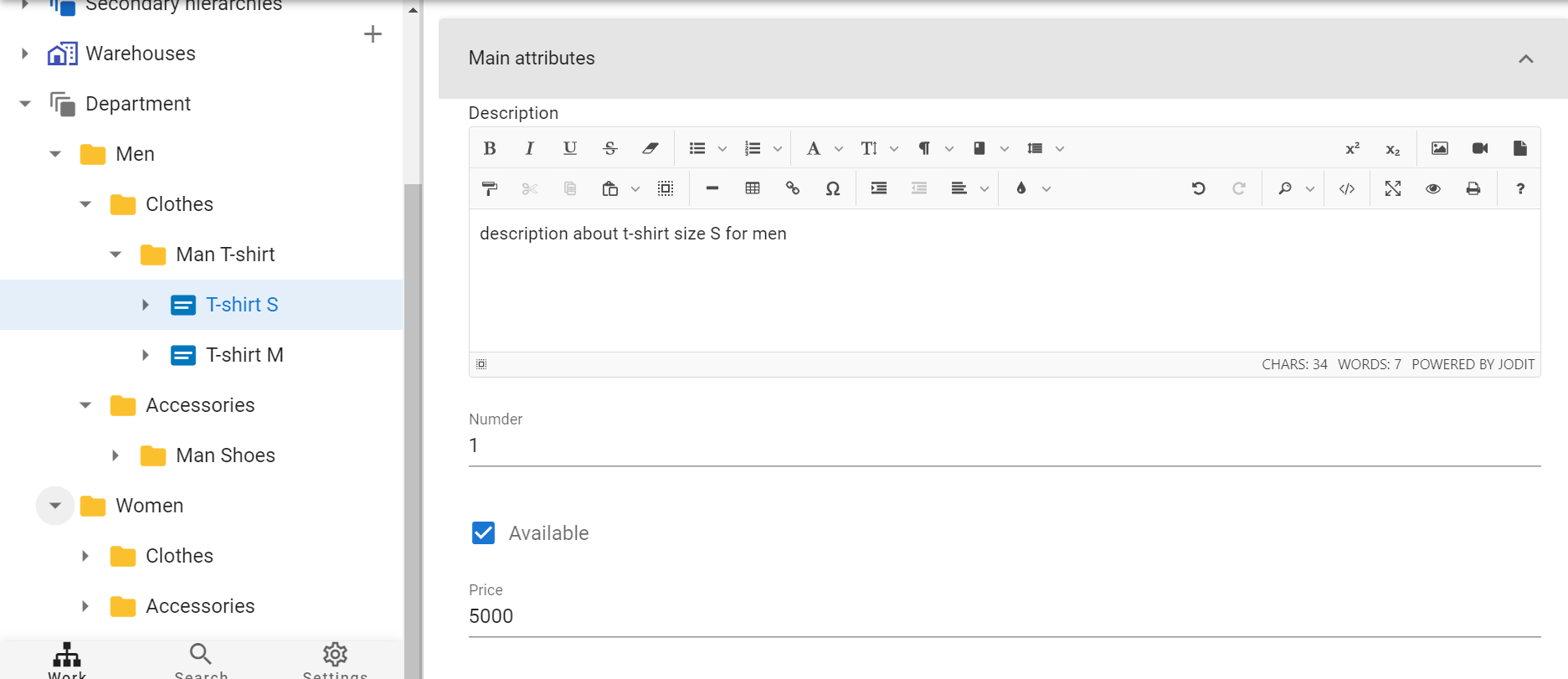
Let's give an example of how you can load data into the system.
For example, let's take this excel file, which contains information about the products that we want to upload and the folders in which they are located. We can also create attributes for the goods:

In order to unload the folders where the products lie we will need 3 schemas, each schema for a different level. We unload the first folder using this scheme:
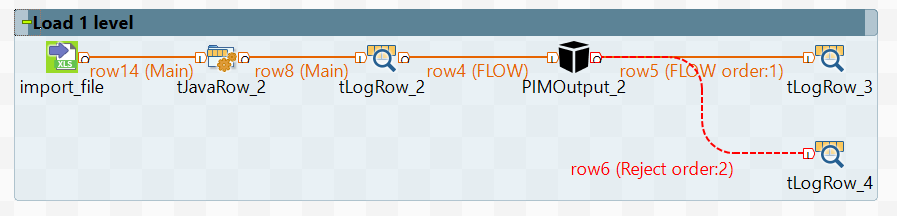
To tFileInputExcel, which contains our excel file, we attach tJavaRow, in which we will prepare the data for the system. For this you need to fill 3 mandatory components and 1 additional one:
identifier- Product ID (must be in English and must not contain spaces)typeIdentifier- The ID of the type. An object of this type will be created.parentIdentifier- The identifier of the parent object. The new object will be created under this parent, or will be created first level object if this column is not specified.name_<language identifier>- This is the name of the object. You can have several columns such as, name_ru, name_en etc for different languages.
Fill tJavaRow with data from excel file, and take missing elements from the system (such as parent and type identifier):

Now, in order to unload what we wrote in tJavaRow, we use the PIMOutput component.
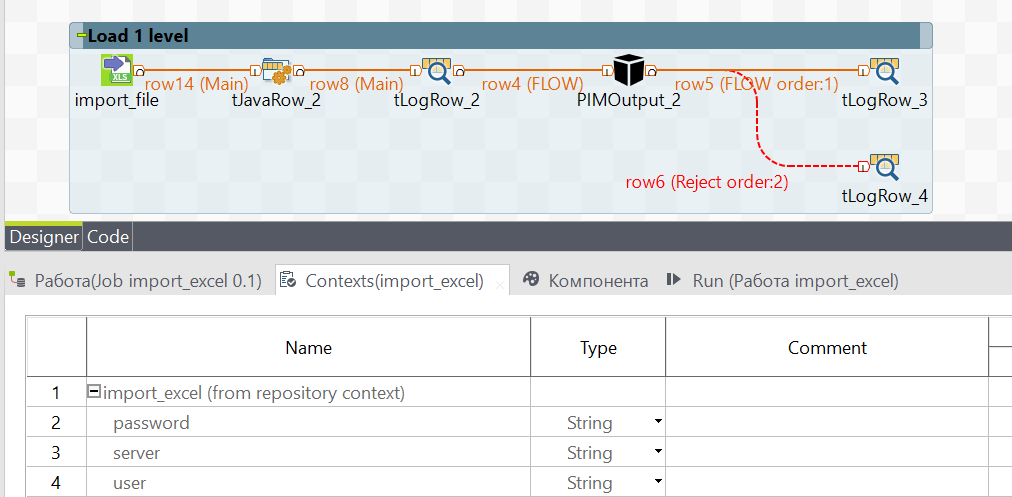
To send the data to a specific server in the context of PIMOutput write the necessary data:
server- url, the path to your server (each company is given a different path);user- username, the user name under which you will be writing;password-password, the password of the user.
Move on to the component tab. It is necessary to fill in all the cells for the unloading of our data specifically.
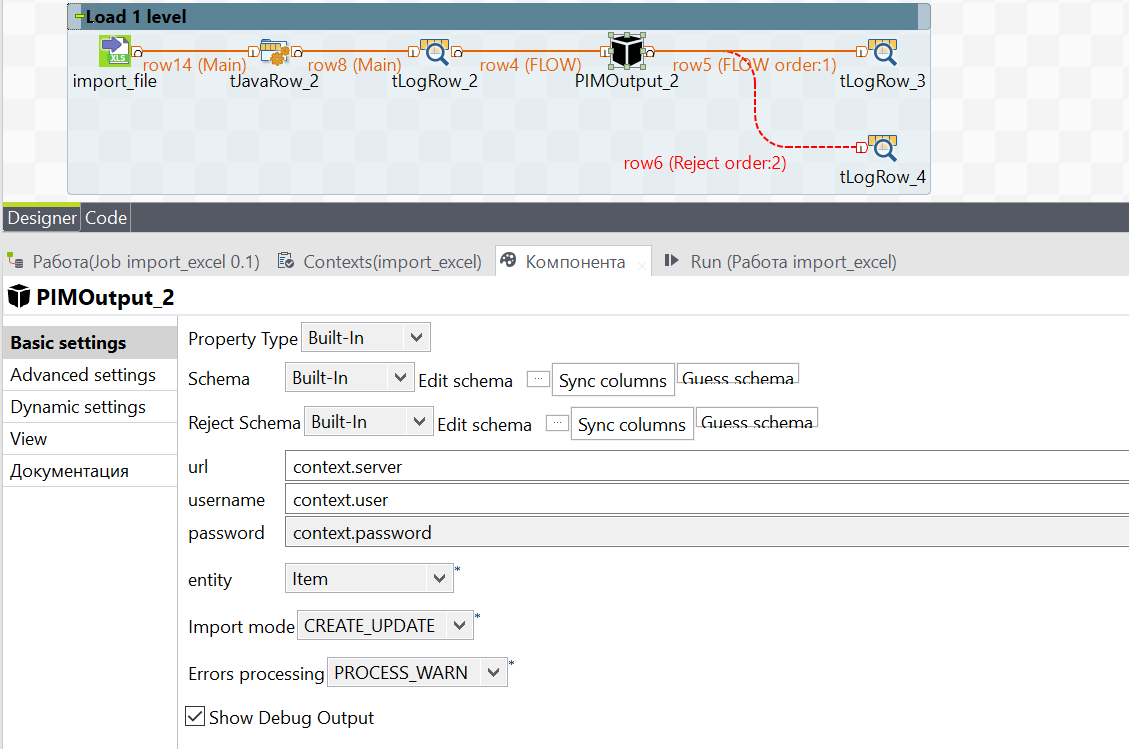
The data url, user and password are taken from the context.
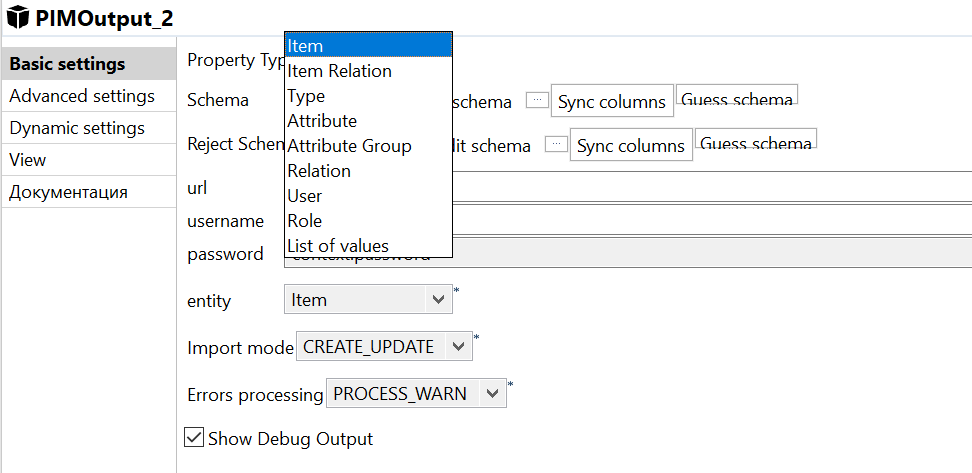
entity - Where the data will be written to. There are different options:
- Item - Object;
- Item Relation - object dependencies;
- Type - Type, Attribute - Attribute;
- Atribute Group - attribute group;
- Relation - dependency;
- User - user;
- Role - the Role;
- List of values - list of values.
In our job we will use Item, because we unload objects.
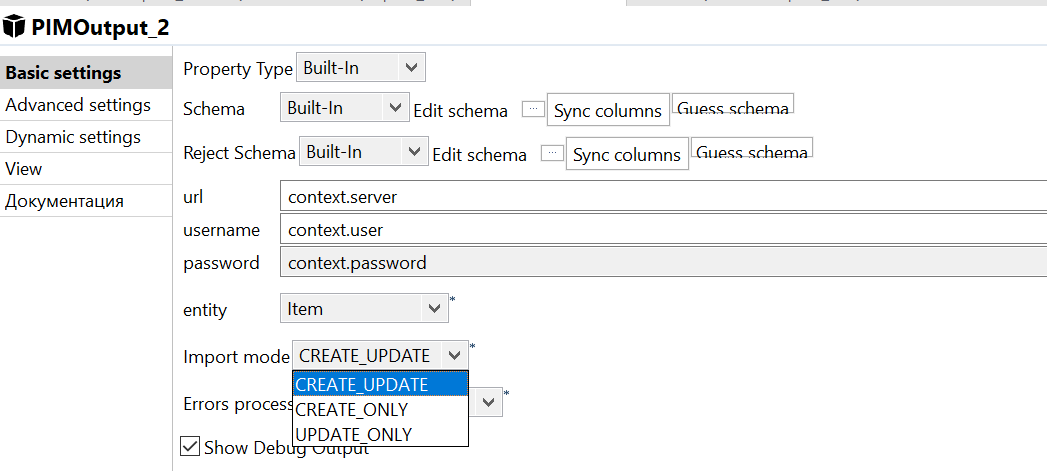
Import mode` - The way the new data will be written. A total of 3 options:
- CREATE_UPDATE - new object will be created if it does not exist, otherwise data of existing one will be updated;
- CREATE_ONLY - the new object will only be created, if this object already exists, an error will occur;
- UPDATE_ONLY - the new object will only be updated, if this object does not exist, an error will occur.
In order to track errors in a file with a lot of information, you can select the Show debug output option. If this option is selected, the system will output additional debug information at run time.
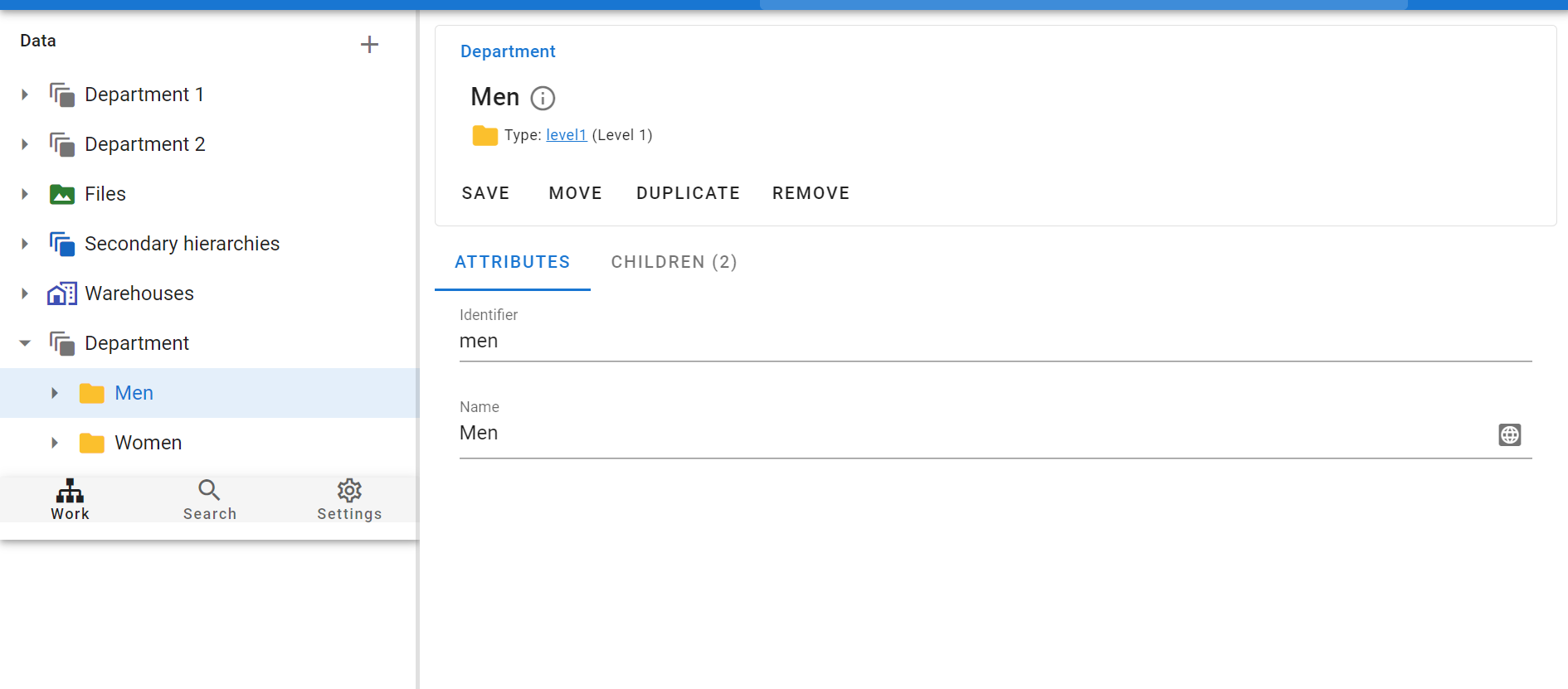
As a result of running this scheme, 2 folders from our excel file will appear in the system at level 1 (level1):
Load the second level
To fill the second level of folders, we create a similar scheme, we will change only tJavaRow.
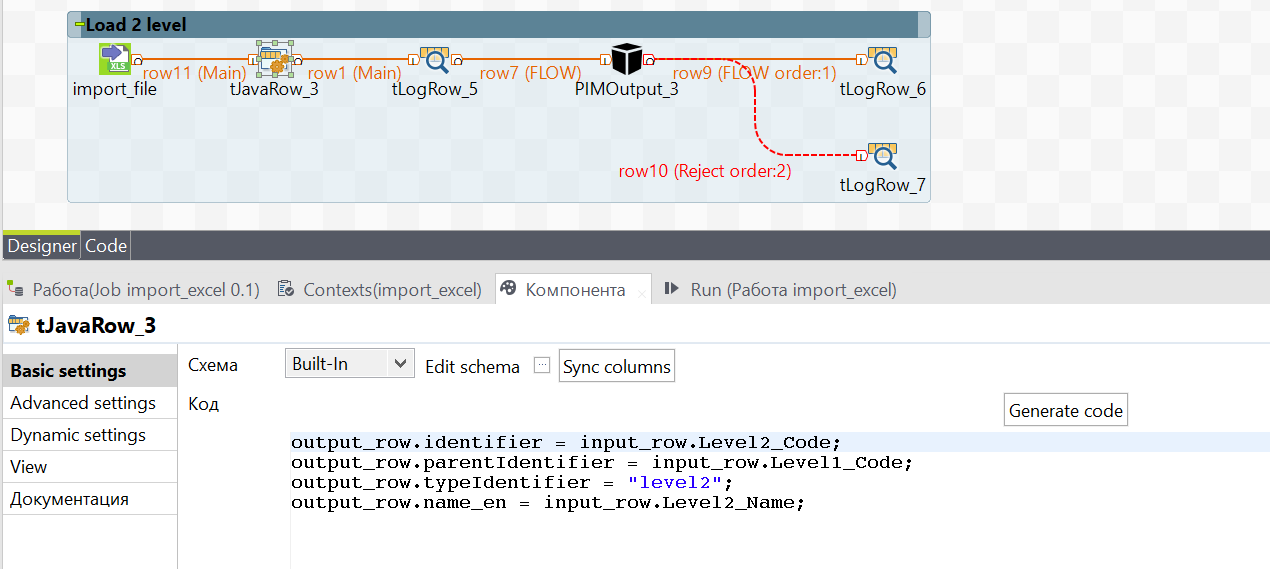
For the folders of level 2 to be located inside level 1, we take the first level of folders as parentIdentifier. typeIdentifier is taken from the system (level2), identifier and name_ru are also taken from the excel file.
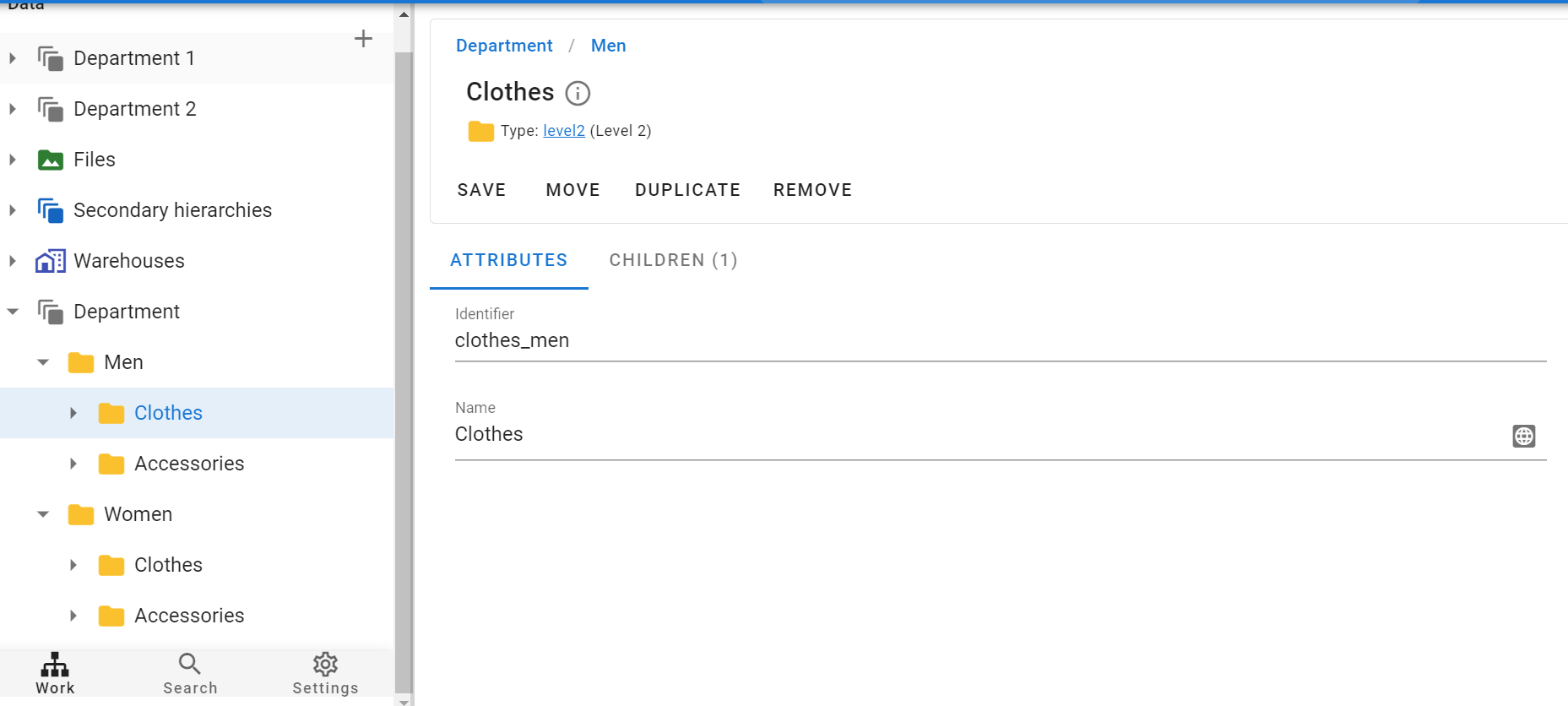
As a result, the level2 folders are placed inside level1, just as we planned.
Load Level 3
To load level 3 folders we do the same as to load level 2. And take the second level of folders as parentIdentifier.
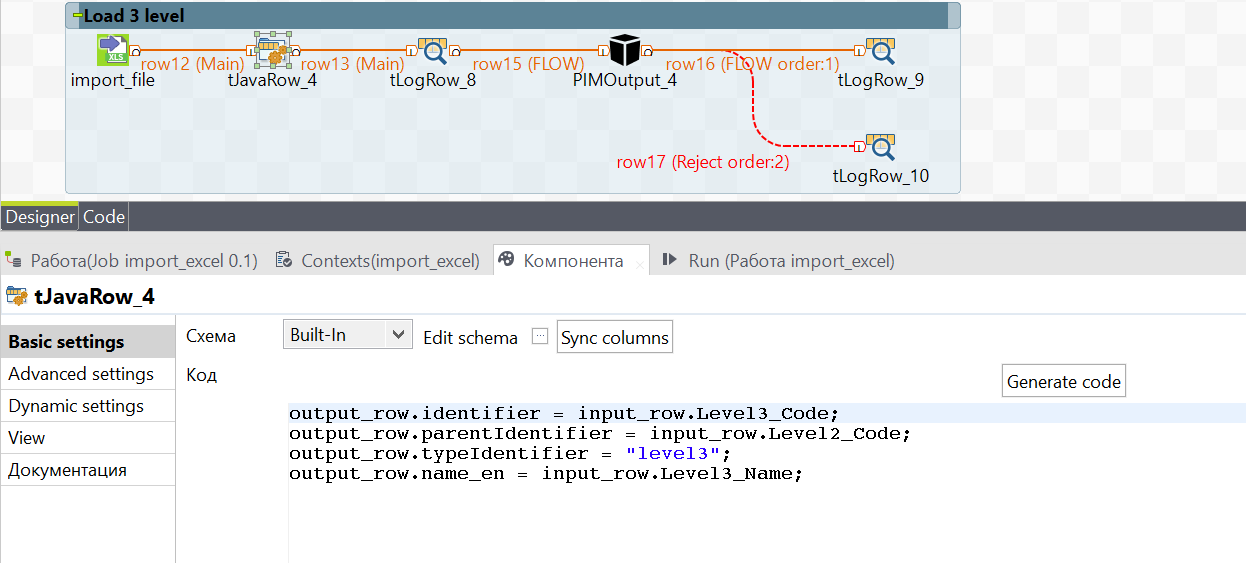
As a result, at this stage we have 3 levels of folders in the system. Since our products and their attributes are on level 3, we can start loading them.
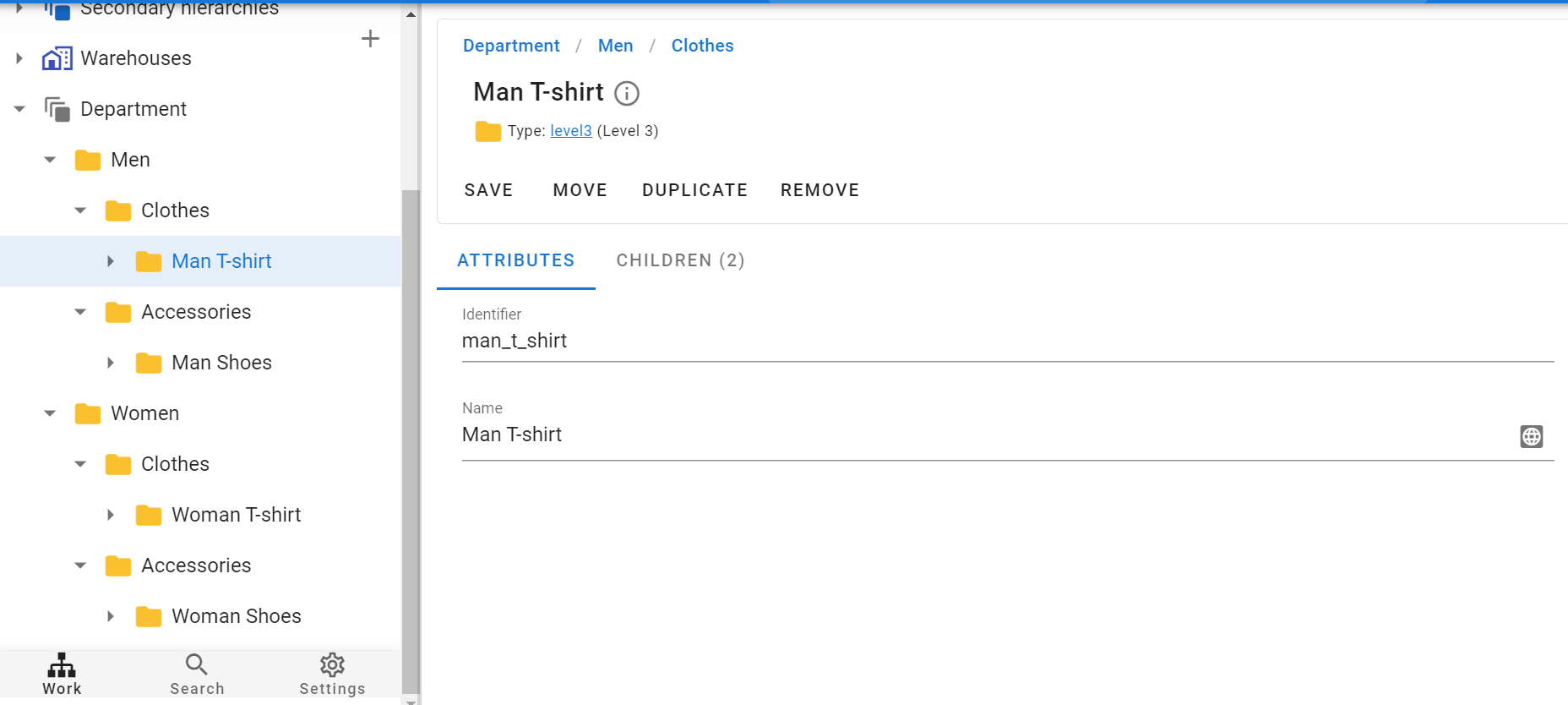
Load goods
To load goods, we still create a similar schema and work only in tJavaRow again.
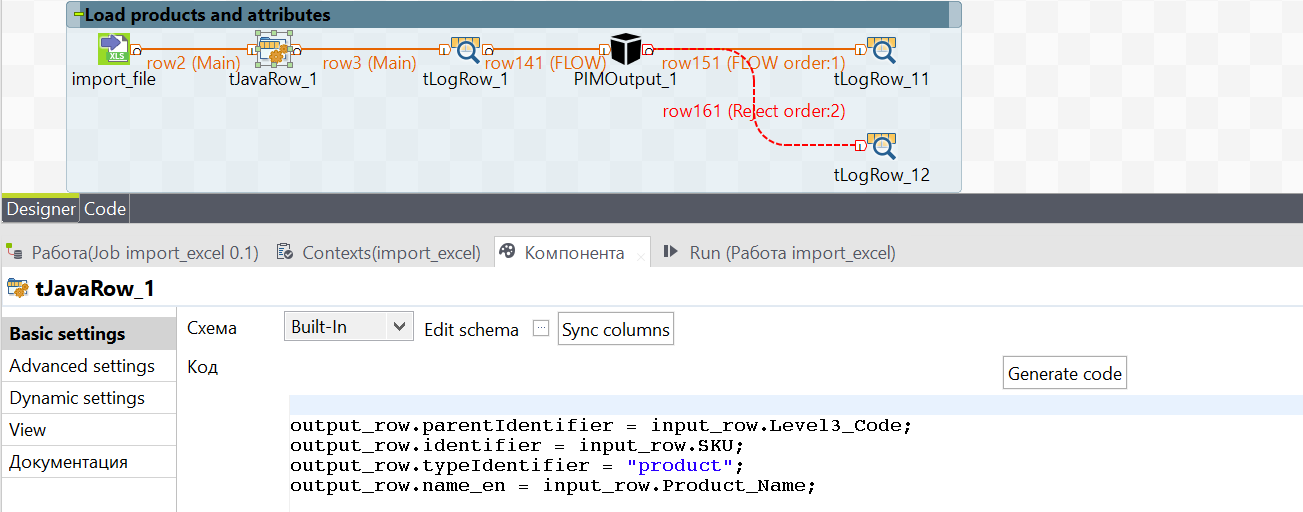
As parentIdentifier (parent), according to the already understood scheme, we take the third level of folders; typeIdentifier this time is not any level, but a product; identifier and name_ru are also taken from the excel file.
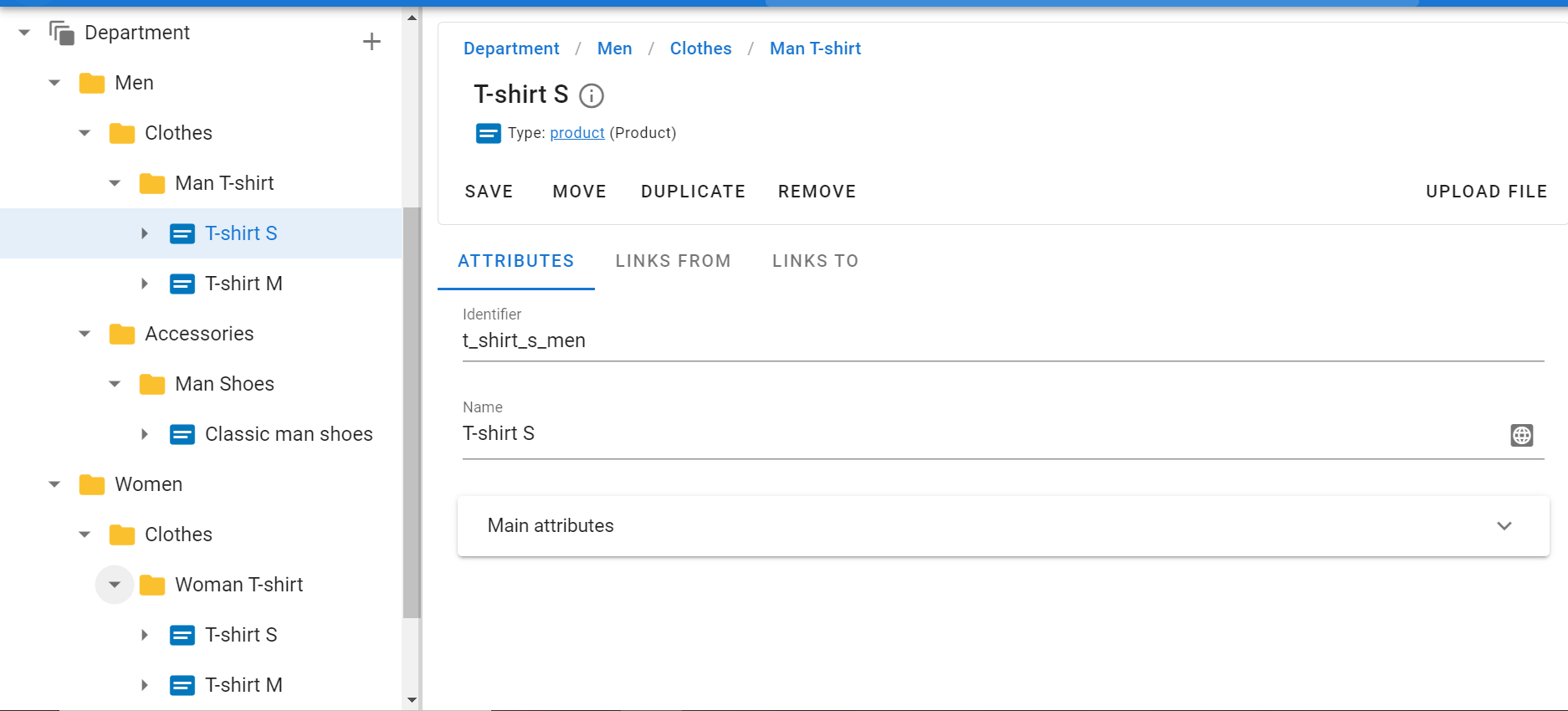
The products are loaded.
But the product has only the name and identifier. And in order to enter any information into it (price, quantity, etc.) it is necessary to load its attributes.
Load product attributes
In order to upload attributes into the system we have to make sure that they are created in the system.
We don't have to create a new schema because the attributes are uploaded to the products. So we augment the previous schema again in tJavaRow.
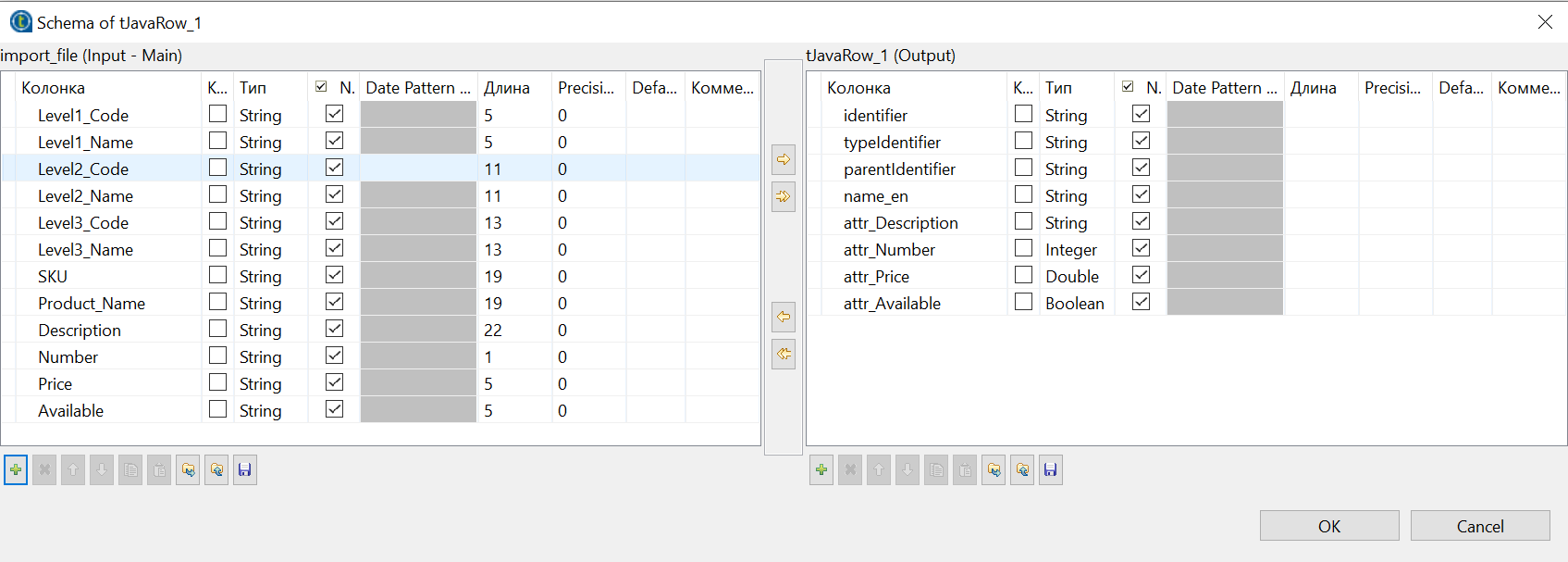
First, in the edit schema in tJavaRow(Output) we put identifier of all attributes from the system in this form - attr_identifier. In the column type put respectively from the system.
To make the attributes appear in the right format (int, string, etc.) You must convert all the output_row into the format they need. If the initial format is string, you can not change it:
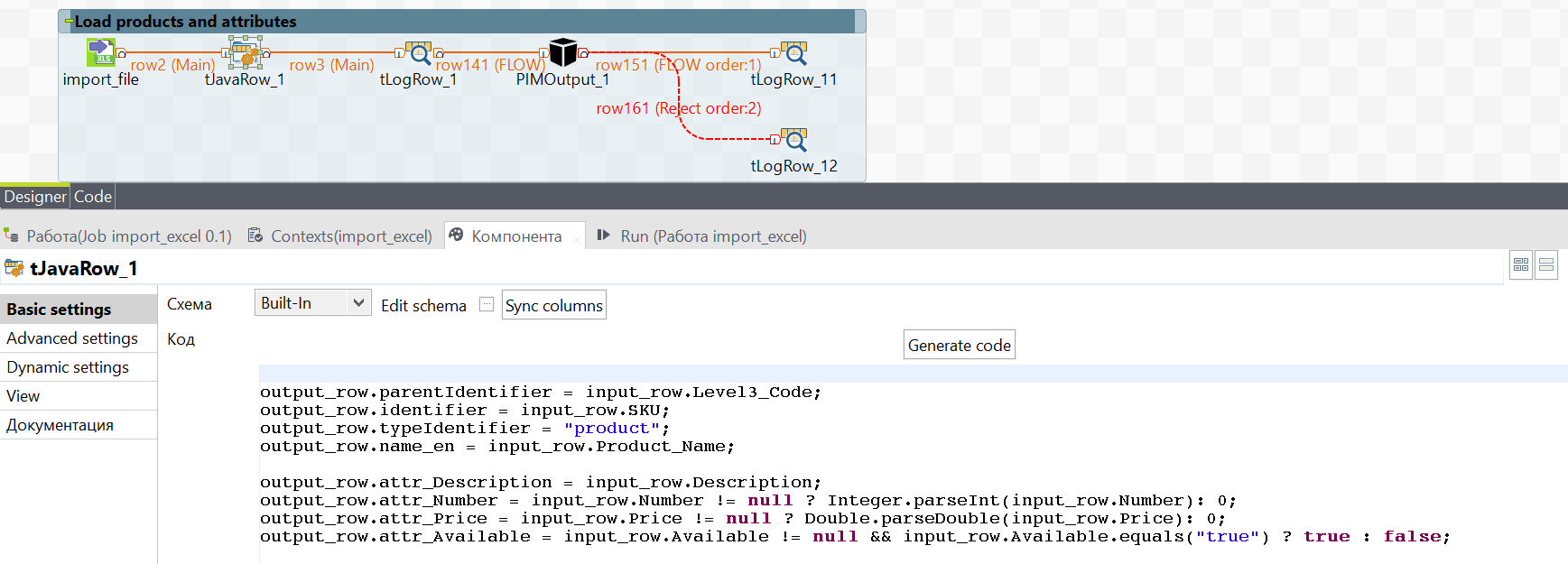
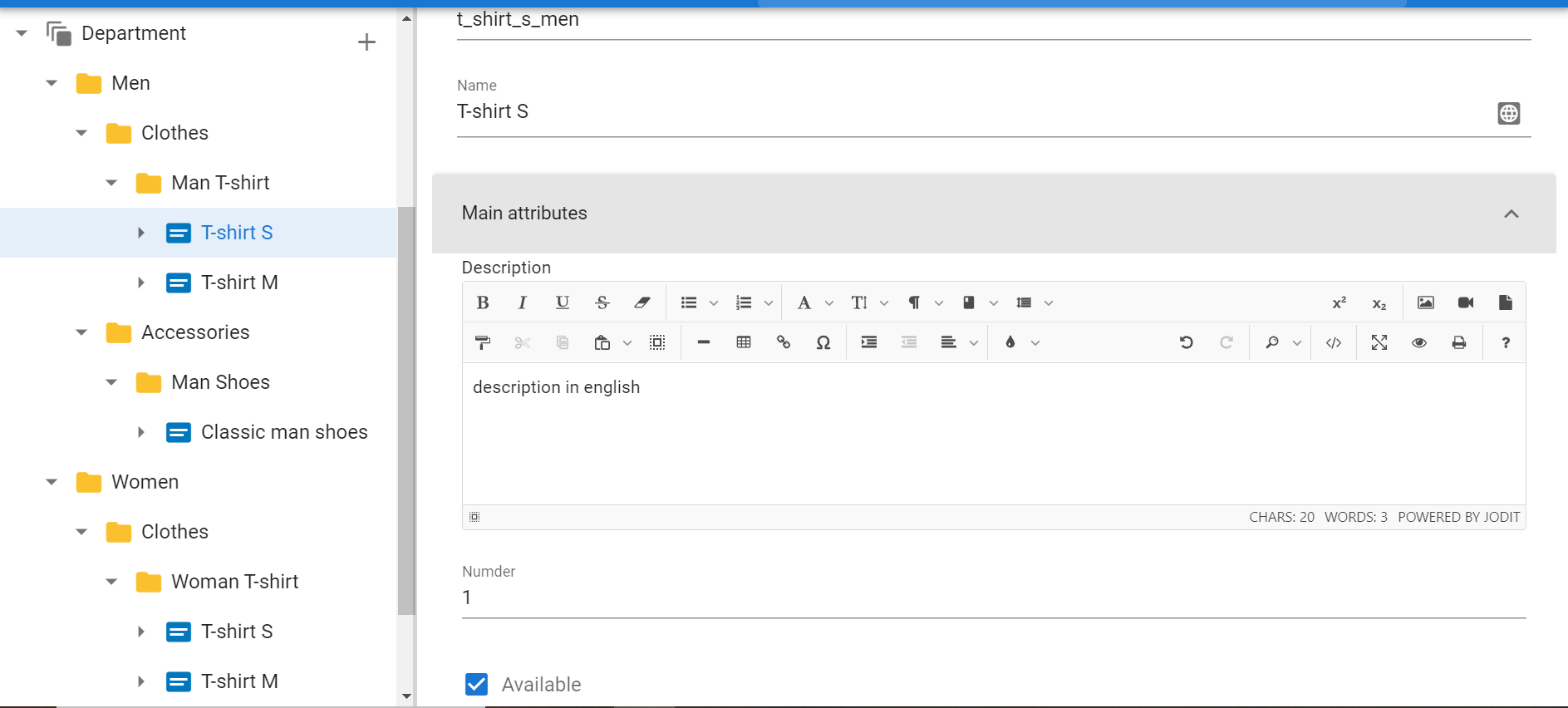
Unload goods into the system again, but now they will fly with the attributes.
Uploading files to the system
Let's give you an example of how you can upload files to the system.
Let's take this excel file as an example:

Let's create a layout to load:
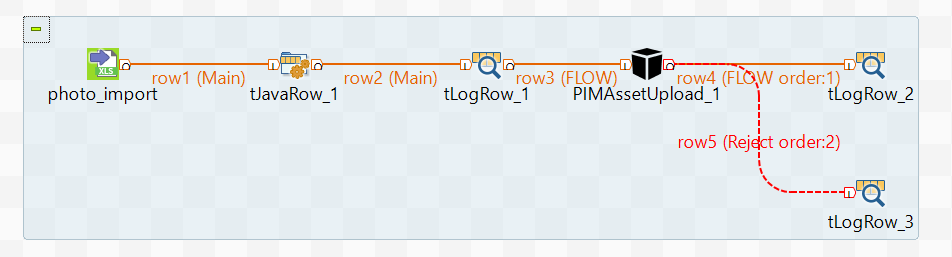
It consists of tFileInput, tJavaRow, tLogRow and a component PIMAssetUpload which will be used to upload the files.
There are 2 columns in the input and output data:
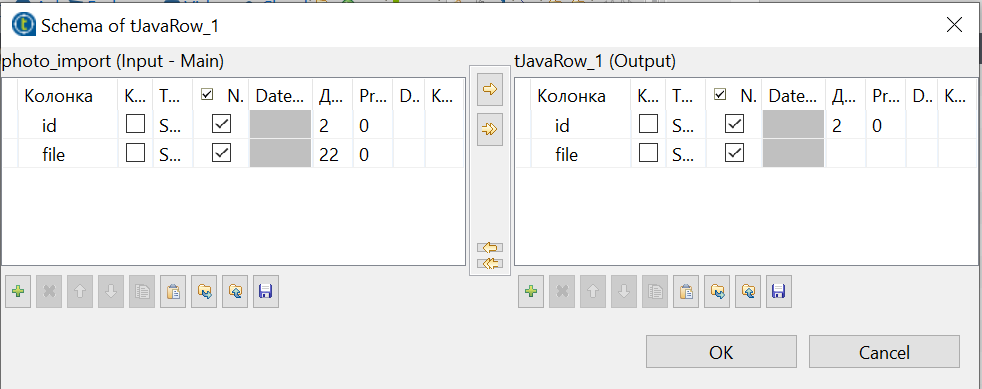
id- id of the type created in the system, in which you can put the file
file- path to the file
If the files are in different folders that are in the same folder, you can specify the beginning of the file path in the context:

To get the data to go into the system, fill in the tJavaRow:

As a result of the scheme, files from excel are flown to the server by their id
Load attributes from another format
Here is an example of a different data attribute upload.
What if for one product you need to unload many attributes and they are not written in the usual form - separate columns, but all in one:

To quickly unload all the attributes, we build this diagram:
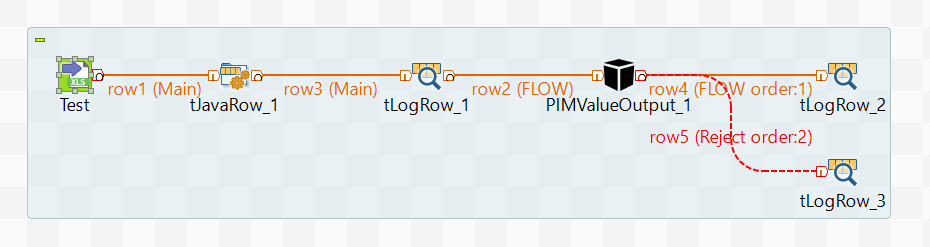
It consists of tFileInput, tJavaRow, tLogRow and the PIMValueOutput component with which we will load the attributes.
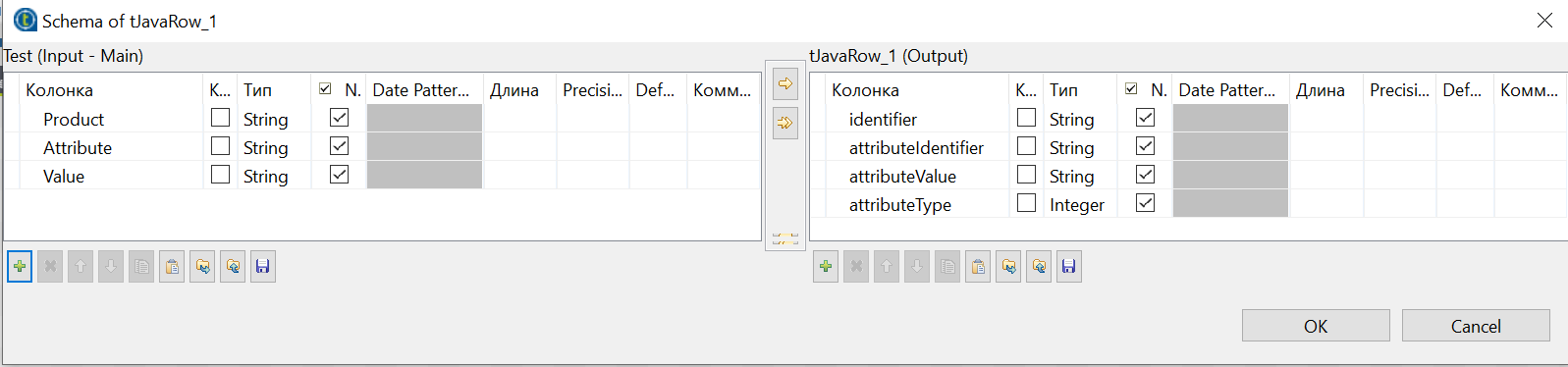
We will use 4 columns as output data:
identifier- the identifier of the product to which the attributes will be written.attributeIdentifier- attribute ID.attributeValue- The value we want to write to the attribute.The
attributeType- type of the attribute. Initially we take an Integer, and in tJavaRow we will specify the type.

We fill in the first three items from the excel file.
PIMValueOutput takes 4 types as follows:
- Text: 1,
- Boolean: 2,
- Integer: 3,
- Float: 4.
To get the system to accept the attributes in the type we want, we write the following code in tJavaRow:

As a result of the scheme, all the attributes will be loaded in the desired type into the system.